








Al descargar archivos, es común encontrar extensiones como .tar, .zip o .gz. Pero, ¿conoces la diferencia entre tar, zip y gz? ¿Por qué los utilizamos y cuál es más eficiente? En el ecosistema Linux, dominar las herramientas zip, tar y gz es fundamental para la gestión de archivos.
Si tienes prisa o simplemente deseas un resumen fácil de recordar, aquí está la diferencia clave:
- .tar == archivo de archivado sin comprimir
- .zip == archivo de archivado (generalmente) comprimido
- .gz == archivo (archivado o no) comprimido mediante gzip
La diferencia principal es que
tarsolo archiva (agrupa archivos) sin comprimir,ziparchiva y comprime en un solo paso, ygz(gzip) es una utilidad que solo comprime un único archivo. En Linux, es común usartarpara archivar y luegogzippara comprimir, creando un archivo.tar.gz.

- Comandos Esenciales para Archivar y Comprimir en Linux
- El Origen de Tar: Historia de los Archivos de Archivado
- La Llegada de la Compresión: Zip y Gzip
- Capacidades y Limitaciones: Cuándo Usar Tar y Cuándo Zip
- Prueba de Eficiencia: Tar vs. Zip vs. Gz
- Recomendación Final: Cuándo Usar Zip, Tar.gz o Tar.xz
Comandos Esenciales para Archivar y Comprimir en Linux
Aunque la teoría es fundamental para entender por qué cada formato existe, la realidad en la administración de sistemas es la línea de comandos. Si eres un SysAdmin o un usuario avanzado, estos son los comandos que utilizarás a diario para archivar y comprimir en Linux.
1. Tarballs (Archivador + Compresión)
Este es el estándar para backups y distribución de software en Linux/Unix, manteniendo la integridad de permisos, usuarios, grupos y estructuras de directorios. Utilizamos la opción -z (gzip), -j (bzip2) o -J (xz) para añadir compresión al archivado.
| Formato | Comprimir (Crear) | Descomprimir (Extraer) | Uso |
|---|---|---|---|
| .tar.gz (o .tgz) | tar -czvf archivo.tar.gz /ruta/archivos | tar -xzvf archivo.tar.gz | Velocidad/Compresión balanceada. |
| .tar.bz2 (o .tbz) | tar -cjvf archivo.tar.bz2 /ruta/archivos | tar -xjvf archivo.tar.bz2 | Mejor compresión que Gzip, más lento. |
| .tar.xz (o .txz) | tar -cJvf archivo.tar.xz /ruta/archivos | tar -xJvf archivo.tar.xz | Máxima compresión, el más lento. |
2. Zip (Compresión y Archivador)
El formato preferido para el intercambio de archivos con sistemas Windows, aunque no preserva completamente los metadatos de Unix.
| Operación | Comando |
|---|---|
| Crear Zip (Recursivo) | zip -r archivo.zip /ruta/archivos |
| Descomprimir Zip | unzip archivo.zip |
El Origen de Tar: Historia de los Archivos de Archivado
Como sucede con muchos elementos de Unix y sistemas similares, la historia comienza hace mucho tiempo, en la década de los setenta. En una fría mañana de enero de 1979, la utilidad tar apareció como parte de la recién lanzada versión Unix V7.
La utilidad tar fue desarrollada como un método para escribir de manera eficiente un gran número de archivos en cinta magnética. Aunque actualmente las unidades de cinta son desconocidas para la gran mayoría de los usuarios individuales de Linux, los tarballs —apodo de los archivos tar— todavía se utilizan ampliamente para empaquetar múltiples archivos o incluso un árbol de directorios completo en un único archivo.
Es importante recordar que un archivo tar estándar es simplemente un archivador; sus datos no están comprimidos. En otras palabras, si archivas 100 archivos de 50 kB cada uno, obtendrás un archivo de aproximadamente 5000 kB. La única ganancia de espacio que puedes esperar al usar solo tar proviene de evitar el desperdicio de espacio del sistema de archivos, ya que la mayoría de ellos asignan espacio con una granularidad específica (por ejemplo, en mi sistema, un archivo de un byte ocupa 4 kB de espacio en disco; 1000 de estos archivos usarían 4 MB, pero el archivo tar correspondiente ocuparía “solo” 1 MB).
Cabe mencionar que tar no es la única herramienta estándar de Unix para crear archivos. Los programadores probablemente conocen ar, ya que hoy en día se utiliza principalmente para crear bibliotecas estáticas, que no son más que archivos de ficheros compilados. Sin embargo, ar puede usarse para crear archivos de cualquier tipo. De hecho, los paquetes .deb utilizados en sistemas Debian son archivos ar. Y en macOS X, los paquetes .mpkg son (¿o eran?) archivos cpio comprimidos con gzip. No obstante, ni ar ni cpio alcanzaron la popularidad de tar entre los usuarios, posiblemente porque el comando tar era suficientemente bueno y fácil de usar.
La Llegada de la Compresión: Zip y Gzip
Crear archivos es útil. Pero con el tiempo, con la llegada de la era de los ordenadores personales, se comprendió que se podía lograr un enorme ahorro de almacenamiento comprimiendo los datos. Así, una década después de la aparición de tar, zip surgió en el mundo de MS-DOS como un formato de archivo que soportaba compresión.
El esquema de compresión más común para zip es DEFLATE, que es una implementación del algoritmo LZ77. Sin embargo, al ser desarrollado comercialmente por PKWARE, el formato zip estuvo sujeto a restricciones de patentes durante años.
Paralelamente, se creó gzip para implementar el algoritmo LZ77 en un programa libre, sin infringir ninguna patente de PKWARE.
Siguiendo un elemento clave de la filosofía de Unix —”Haz una sola cosa y hazla bien”—, gzip fue diseñado únicamente para comprimir archivos. Por lo tanto, para crear un archivo comprimido, primero se debe crear el archivo (por ejemplo, con la utilidad tar) y, posteriormente, comprimir dicho archivo.
El resultado es un fichero .tar.gz (a veces abreviado como .tgz). Entender esto es clave para saber qué es un archivo tar.gz: es un archivo tar que ha sido comprimido con gzip.
A medida que la informática avanzaba, se desarrollaron otros algoritmos que ofrecían tasas de compresión superiores. Por ejemplo, el algoritmo Burrows-Wheeler, implementado en bzip2 (lo que dio lugar a los archivos .tar.bz2), o el más reciente xz, que es una implementación del algoritmo LZMA, similar al utilizado en la utilidad 7-Zip. Si necesitas trabajar con este último, puedes consultar mi guía sobre cómo descomprimir archivos .tar.xz.
Capacidades y Limitaciones: Cuándo Usar Tar y Cuándo Zip
Actualmente, puedes utilizar libremente cualquier formato de archivo tanto en Linux como en Windows.
Dado que el formato zip es soportado de forma nativa en Windows, es especialmente común en entornos multiplataforma. Incluso se puede encontrar en lugares inesperados. Por ejemplo, fue adoptado por Sun para los archivos JAR, utilizados para distribuir aplicaciones Java compiladas, y para los archivos OpenDocument (.odt, .odp, etc.) que usan LibreOffice y otras suites ofimáticas. Todos estos formatos son archivos zip disfrazados. Si tienes curiosidad, no dudes en descomprimir uno para ver su contenido:
sh$ unzip archivo-cualquiera.odt
Archive: archivo-cualquiera.odt
extracting: mimetype
inflating: meta.xml
inflating: settings.xml
inflating: content.xml
[...]
inflating: styles.xml
inflating: META-INF/manifest.xmlA pesar de todo, en el mundo de los sistemas tipo Unix, yo seguiría prefiriendo un archivo de tipo tar, ya que el formato zip no soporta de manera fiable todos los metadatos del sistema de archivos de Unix. Para una explicación concreta de esta afirmación, debes saber que el formato ZIP solo define un pequeño conjunto de atributos de archivo obligatorios para cada entrada: nombre de archivo, fecha de modificación y permisos.
Además de estos atributos básicos, un archivador puede almacenar metadatos adicionales en el llamado “campo extra” de la cabecera ZIP. Pero como los campos extra son definidos por la implementación, no hay garantía de que diferentes archivadores almacenen y extraigan el mismo conjunto de metadatos.
Verifiquémoslo con un ejemplo:
sh$ ls -lsn data/team
total 0
0 -rw-r--r-- 1 1000 2000 0 Jan 30 12:29 team
sh$ zip -0r archive.zip data/
sh$ zipinfo -v archive.zip data/team
Central directory entry #5:
---------------------------
data/team
[...]
apparent file type: binary
Unix file attributes (100644 octal): -rw-r--r--
MS-DOS file attributes (00 hex): none
The central-directory extra field contains:
- A subfield with ID 0x5455 (universal time) and 5 data bytes.
The local extra field has UTC/GMT modification/access times.
- A subfield with ID 0x7875 (Unix UID/GID (any size)) and 11 data bytes:
01 04 e8 03 00 00 04 d0 07 00 00.Como puedes observar, la información del propietario (UID/GID) forma parte del campo extra. Esto puede no ser evidente si no conoces el sistema hexadecimal o que los metadatos ZIP se almacenan en formato little-endian, pero para abreviar: e803 es 03e8, que equivale a 1000 (el UID del archivo), y d007 es 07d0, que equivale a 2000 (el GID del archivo).
En este caso específico, la herramienta zip de Info-ZIP en mi sistema Debian guardó algunos metadatos útiles en el campo extra. Sin embargo, no hay garantía de que cada archivador escriba este campo, y aunque lo haga, no hay garantía de que la herramienta utilizada para extraer el archivo lo interprete correctamente.
Si bien no podemos descartar la tradición como una motivación para usar tarballs, con este pequeño ejemplo entiendes por qué todavía existen casos (¿fundamentales?) en los que tar no puede ser reemplazado por zip. Esto es especialmente cierto cuando se desea preservar todos los metadatos estándar de un archivo, como los permisos que se gestionan con el comando chmod.
Prueba de Eficiencia: Tar vs. Zip vs. Gz
Aquí me referiré a la eficiencia en el uso del espacio, no del tiempo, aunque, por regla general, un algoritmo de compresión es potencialmente más eficiente cuanto mayor es el uso de CPU que requiere.
Para darte una idea del nivel de compresión obtenido con diferentes algoritmos, he recopilado unos 100 MB de archivos de formatos populares de mi disco duro. Aquí está el resultado obtenido en mi sistema Debian Stretch (todos los tamaños se midieron con du -sh):
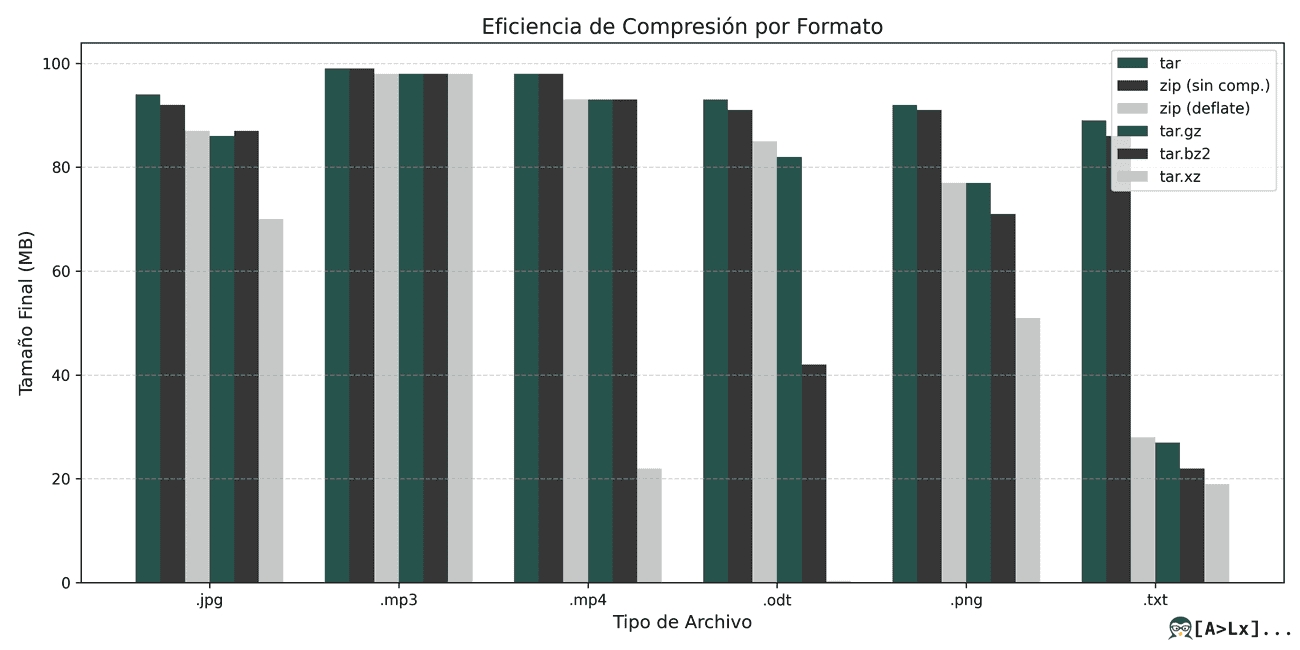
| Tipo de Archivo | Número de Archivos | Espacio en Disco (Original) | tar | zip (sin comp.) | zip (deflate) | tar + gzip | tar + bz2 | tar + xz |
|---|---|---|---|---|---|---|---|---|
| .jpg | 216 | 98M | 94M | 92M | 87M | 86M | 87M | 70M |
| .mp3 | 345 | 99M | 99M | 99M | 98M | 98M | 98M | 98M |
| .mp4 | 279 | 99M | 98M | 98M | 93M | 93M | 93M | 22M |
| .odt | 20 | 98M | 93M | 91M | 85M | 82M | 41M | 348K |
| .png | 724 | 98M | 92M | 91M | 77M | 77M | 71M | 51M |
| .txt | 397 | 98M | 89M | 86M | 28M | 27M | 22M | 19M |
En primer lugar, te insto a tomar estos resultados con cautela: los archivos de datos eran ficheros que tenía en mi disco duro y de ninguna manera afirmaría que son representativos. Además, debo admitir que no elegí estos tipos de archivo al azar.
Como mencioné, los archivos .odt ya son archivos zip. Por lo tanto, no es sorprendente la modesta ganancia obtenida al comprimirlos por segunda vez (con la excepción de bzip2 o xz, que consideraría una anomalía estadística causada por la baja heterogeneidad de mis datos, que contenían varias copias de seguridad o versiones de los mismos documentos).
En cuanto a .jpg, .mp3 y .mp4, es posible que sepas que ya son formatos de datos comprimidos. Mejor aún si has oído que utilizan compresión con pérdida. Esto significa que después de comprimir un JPEG, no puedes reconstruir la imagen original con exactitud. Y es cierto. Pero un hecho menos conocido es que, tras la fase de compresión con pérdida, los datos se comprimen una segunda vez con un algoritmo de Huffman sin pérdida para eliminar la redudancia.
Por estas razones, era de esperar que comprimir imágenes JPEG o archivos MP3/MP4 no arrojara resultados significativos. Ten en cuenta que, como un archivo típico contiene tanto datos altamente comprimidos como algunos metadatos sin comprimir, todavía podemos obtener una pequeña ganancia.
Esto explica por qué obtuve una mejora notable con las imágenes JPEG, ya que tenía muchas y el tamaño total de los metadatos no era insignificante en comparación con el tamaño total de los archivos. De nuevo, los sorprendentes resultados al comprimir archivos MP4 con xz probablemente se deban a la gran similitud entre los diferentes archivos MP4 utilizados en mis pruebas. ¿O no?
Para despejar estas dudas, te recomiendo encarecidamente que realices tus propias comparaciones. ¡Y no dudes en compartir tus observaciones con nosotros en la sección de comentarios!
Recomendación Final: Cuándo Usar Zip, Tar.gz o Tar.xz
La elección entre tar.gz, tar.xz o zip siempre debe responder a la intención de uso y al ecosistema destino de los datos. La comparativa tar vs zip en Linux tiene un claro ganador según el contexto.
Si el objetivo es la administración de servidores, backups internos o distribución de software en el ecosistema GNU/Linux, el binomio tar más una utilidad de compresión es innegociable. Específicamente, el tar.gz es el caballito de batalla por su equilibrio entre velocidad y tasa de compresión. Sin embargo, para aquellos escenarios donde el tamaño final es crítico y el tiempo de compresión es secundario (como un archivado de datos históricos), los resultados de nuestra prueba muestran que tar.xz es el claro ganador en eficiencia de espacio para la mayoría de archivos estructurados.
En cambio, si su misión es intercambiar archivos con usuarios de sistemas operativos no Unix (Windows/macOS), el formato .zip es la solución más práctica por su soporte nativo. Es una concesión necesaria, ya que debe priorizarse la accesibilidad sobre la estricta conservación de metadatos de archivos de Unix.








¿Qué te parece?
Es bueno conocer tu opinión. Deja un comentario.